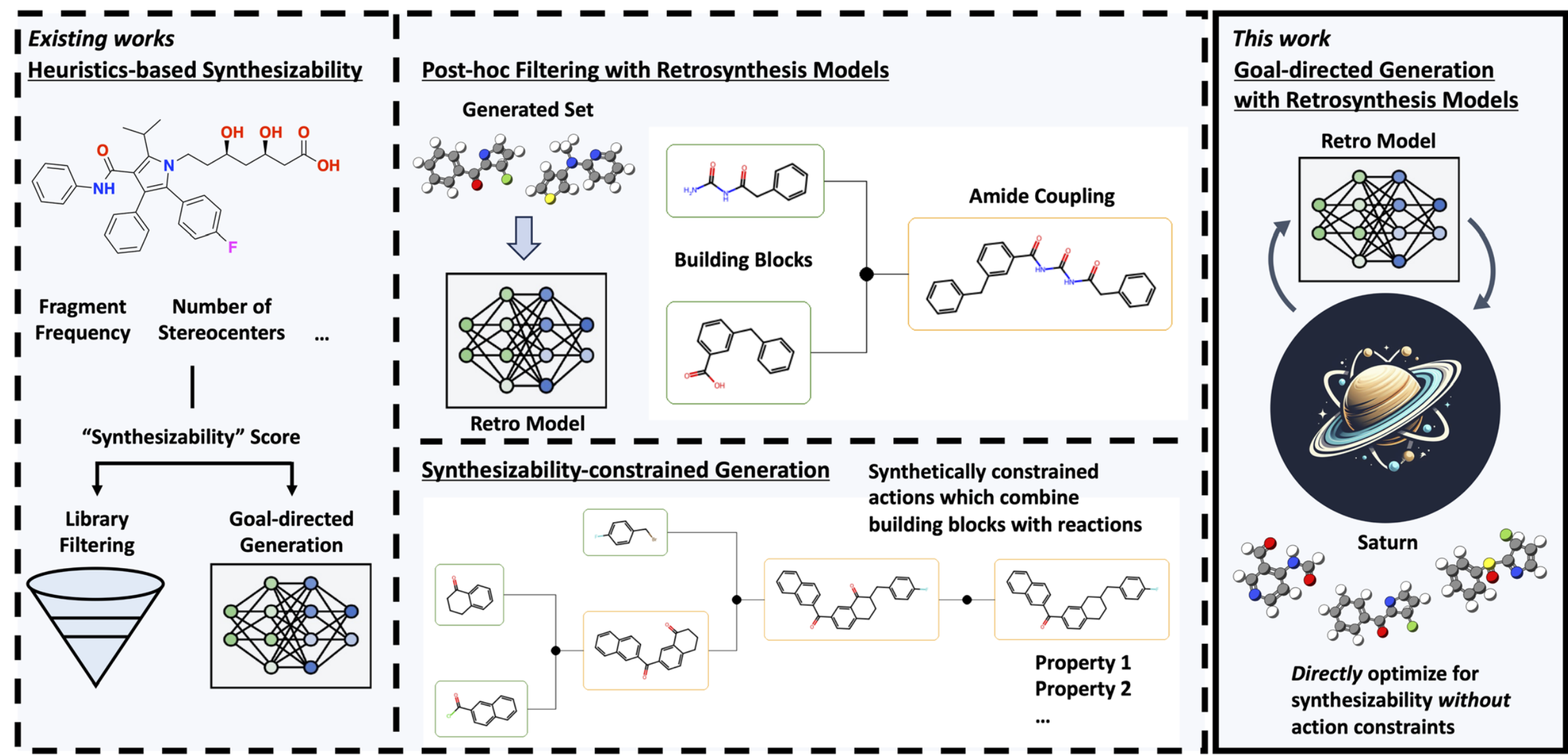
分子生成模型已经能优化活性、性质和多目标指标,但真正落地前必须先回答一个问题:这些分子能不能合成 现有常见做法有三类:用 SA score 等启发式指标、生成后再做 retrosynthesis 过滤、或直接把生成空间限制在反应模板内 本文真正要解决的不是“再造一个逆合成模型”,而是回答能否把 retrosynthesis 直接作为生成优化里的 oracle 作者的判断是:只要生成模型足够 sample-efficient,这件事是可行的
作者先给出一个反例:如果目标函数里只有 docking score,模型会快速学会利用 oracle 的漏洞 这类分子通常分子量更大、疏水性更强、QED 更差,看起来分数高,但并不是真正有价值的候选 这说明在生成任务中,单一性质优化很容易走向“伪优”区域 因此后续必须同时引入可合成性和更合理的多目标约束
生成器使用 Saturn,这是一个基于 Mamba 的自回归分子生成模型,优势是 sample efficiency 高 可合成性不再只做后处理,而是把 retrosynthesis 模型的 solvability 直接写进 reward 论文强调方法对 retrosynthesis 模型形式不敏感,后面分别接了 AiZynth、RetroKNN、Graph2Edits、RootAligned 这篇工作真正的新意是范式变化:从“生成后检查能不能合成”,变成“生成时就朝可合成方向搜索” 组件 本文做法 生成模型 Saturn 可合成性 oracle retrosynthesis solvability 下游任务 药物发现与功能材料 核心问题 直接优化是否在现实预算下可行
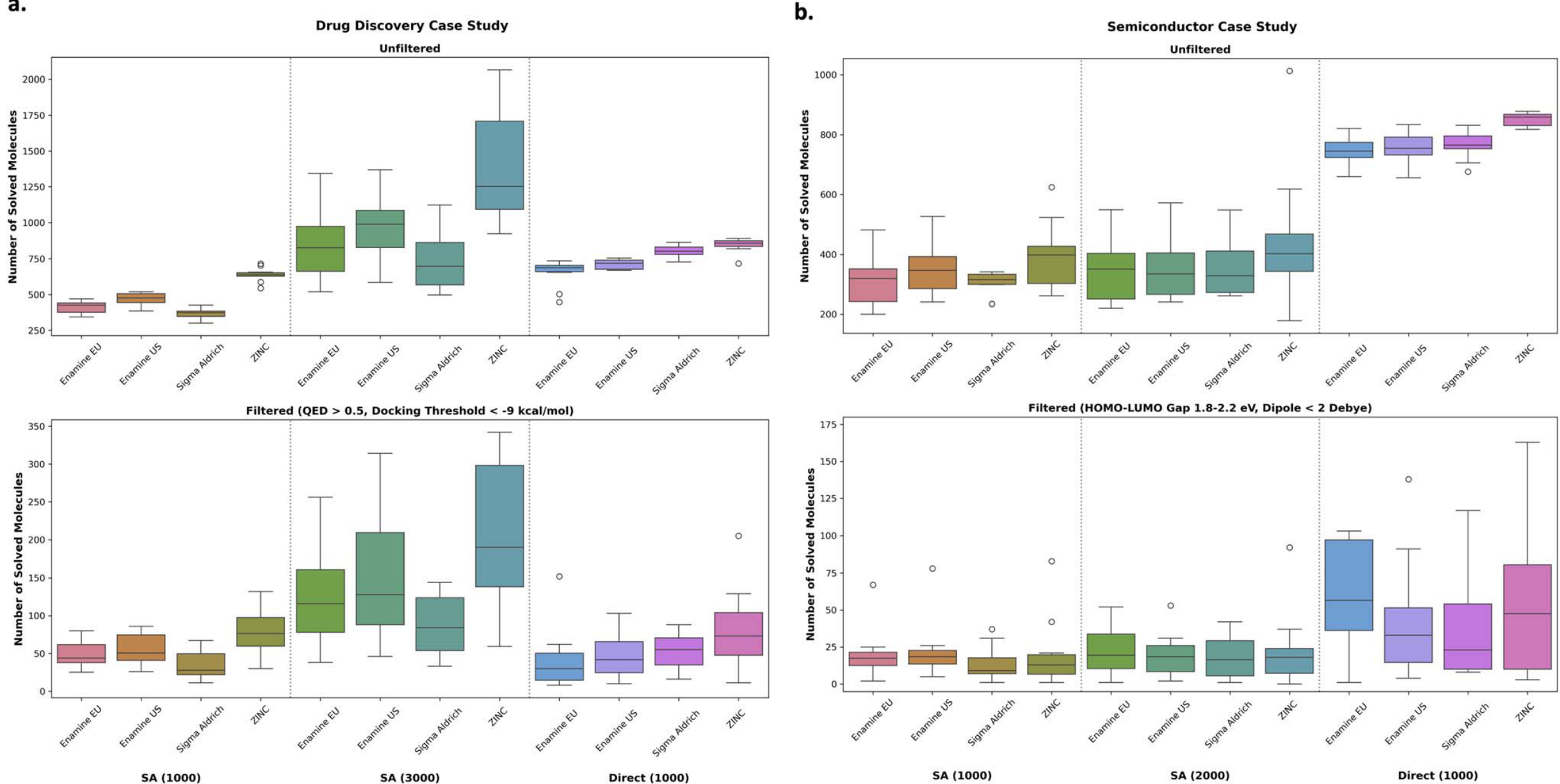
四目标版本同时优化 docking、QED、SA 和 retrosynthesis solvability,对应更平衡但更难的优化任务 双目标版本只优化 docking 和 solvability,更容易找到更多可行 mode,但不会主动保证 QED 等性质 实验覆盖六个问题:从“只优化 docking 的失败例子”,一直到“什么时候启发式失效、什么时候直接优化更值得” 两个主要场景分别是药物发现任务和功能材料任务,后者是全文最关键的泛化检验 目标函数 主要作用 R_all MPO 同时追求性质均衡与可合成性 R_double MPO 检查直接优化 solvability 的上限与效率 SA / QED 代理目标 对比启发式与真实 retrosynthesis 的差异
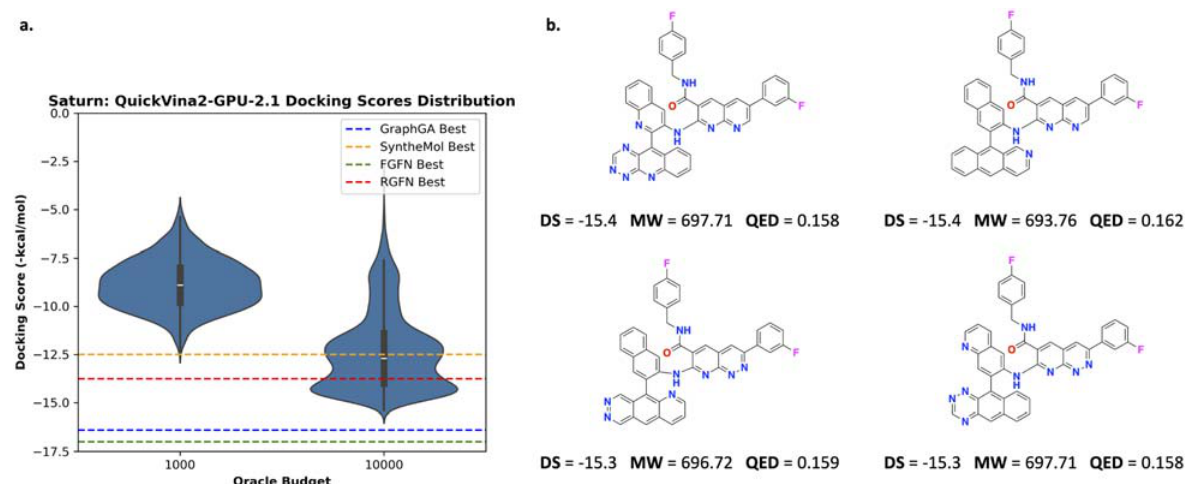
这是论文最核心的结果:在只有 1000 次分子评估的条件下,直接把 AiZynth 放进优化目标,依然能得到可解路线的候选 四目标版本得到的分子更均衡,双目标版本能找到更多 mode,但 QED 明显下降 这说明“直接优化 retrosynthesis 很贵,所以不现实”并不是绝对成立,关键在生成器的样本效率 但作者也很诚实地指出:对 drug-like 分子来说,是否值得这样做,还要看和启发式相比的性价比 配置 关键结论 R_all MPO mode 数较少,但性质更平衡,候选更“能直接用” R_double MPO mode 更多,solvability 也高,但更容易牺牲 QED 和 RGFN 等对比 更低预算下已经能找到高质量可合成候选
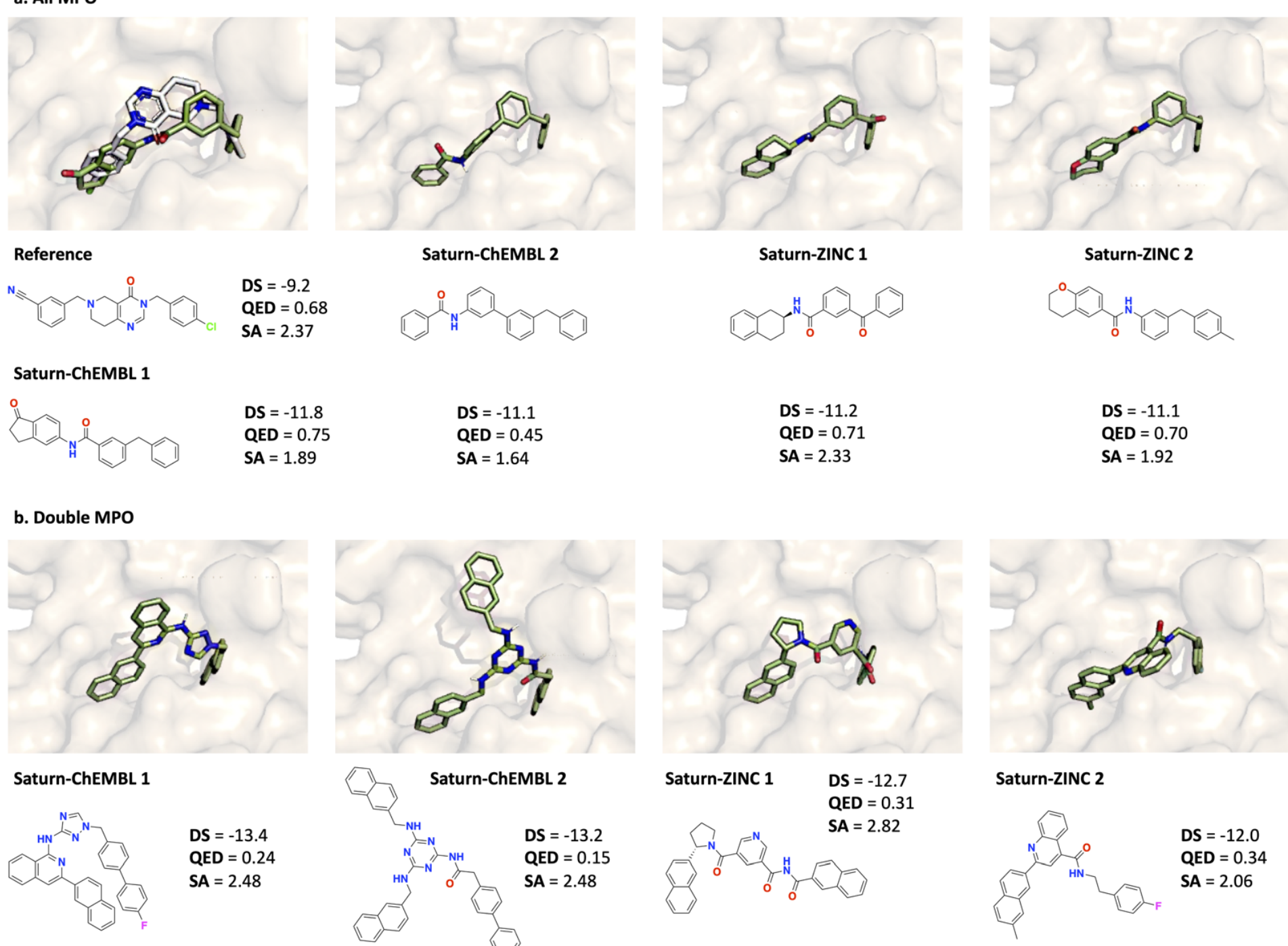
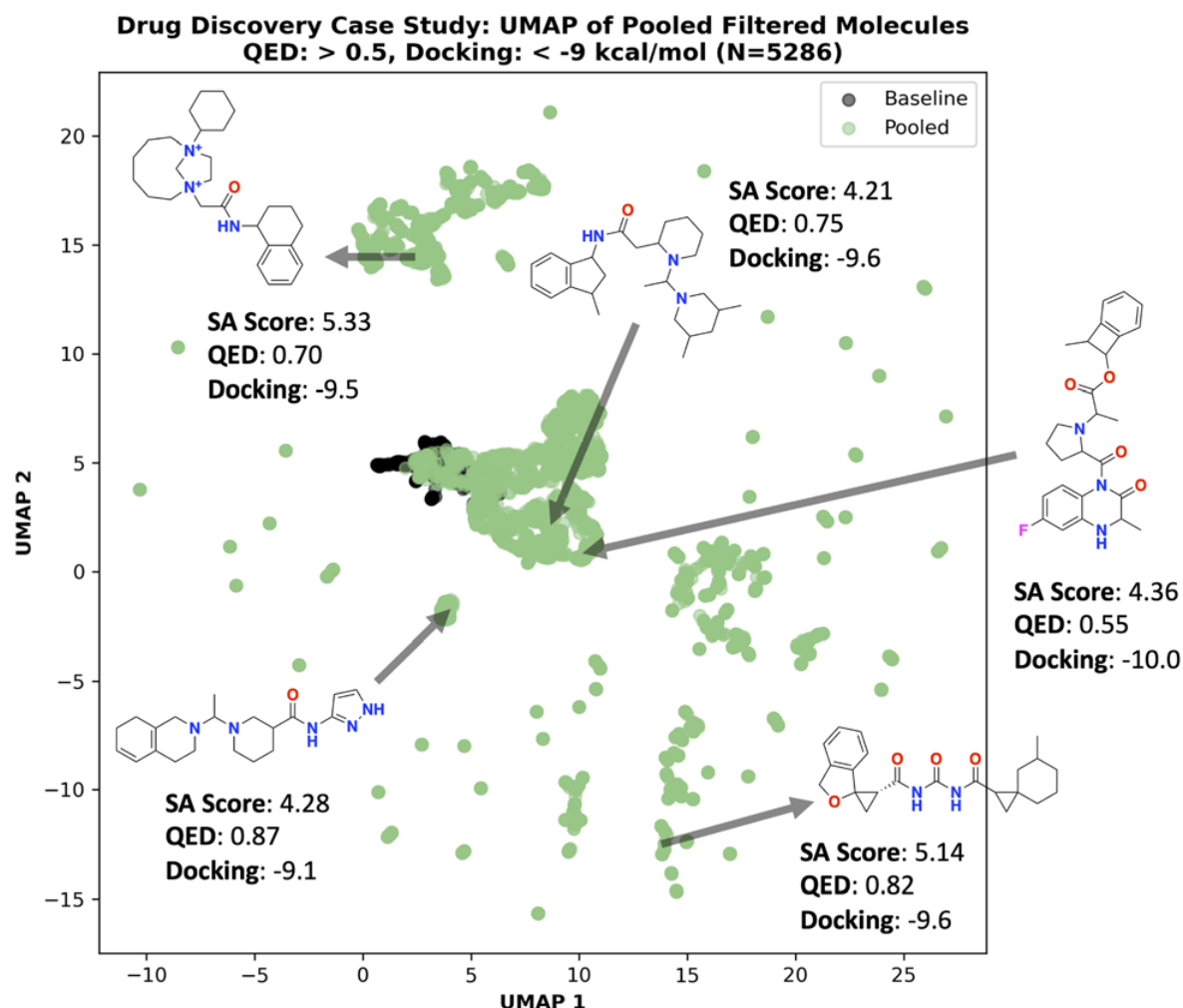
这一页不是在证明 docking 更准,而是在说明模型没有只学到表面分数,而是真的找到了一批结构上可解释的候选 图中展示的是不同 Saturn 配置下 docking score 最优的分子及其 pose 这些分子不仅分数好,而且都能被 AiZynth 求解,这让“性质优化”和“可合成性约束”第一次在同一个闭环里统一起来 同时也能看出,只优化 docking 和 solvability 的版本更容易走向更激进的结构
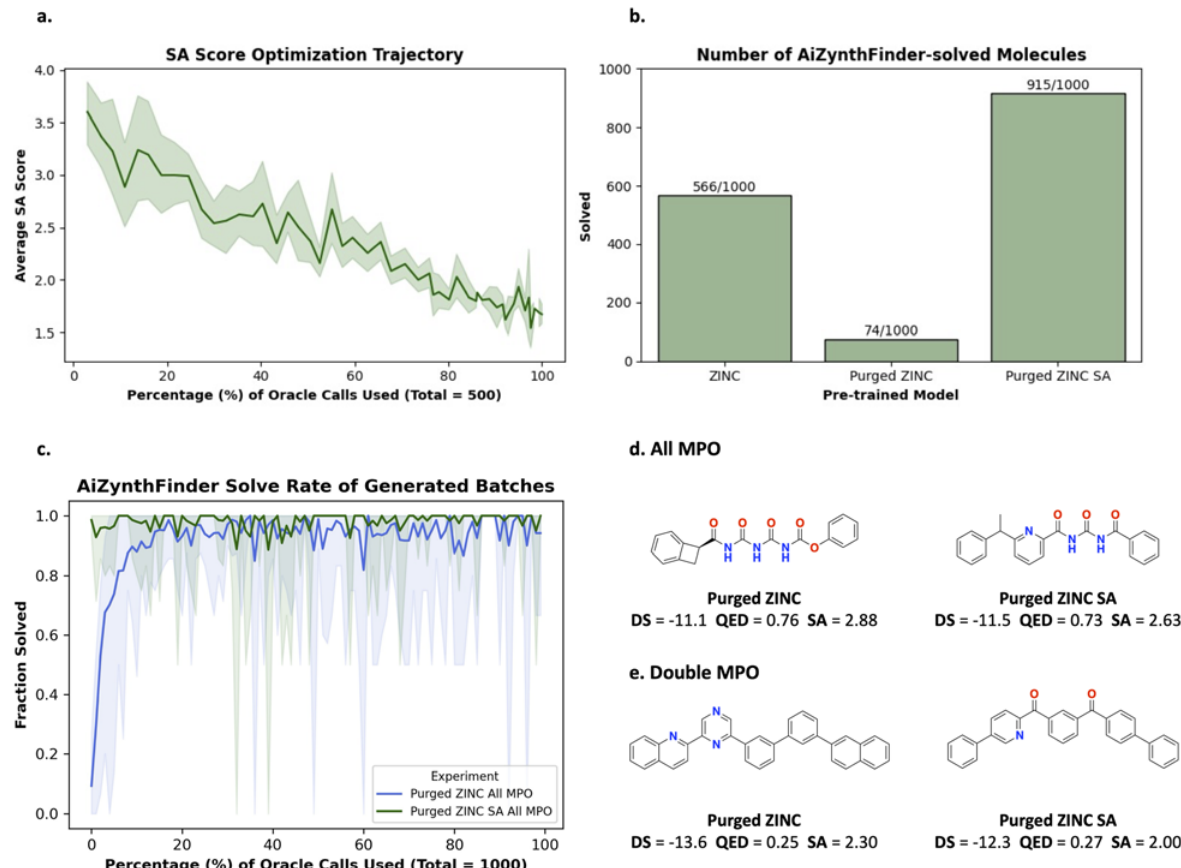
作者故意构造了一个更难的起点:把预训练数据里能被 AiZynth 求解的分子全部剔除,再重新训练生成模型 按直觉,这样的模型应当更容易生成不可合成分子,但作者用一个简单的 curriculum learning 把它拉了回来 做法是先让模型学会优化 SA score,再切换到带 retrosynthesis 的目标,结果很快恢复到高 solvability 区域 这说明直接优化这条路线并不只依赖“幸运的训练分布”,而是有一定鲁棒性
这是全文最有价值的结论:是否值得把 retrosynthesis 放进闭环,不是统一答案,而是取决于任务分布 在 drug-like 分子任务里,SA score 这类启发式和 solvability 仍然有较强相关性,因此“先优化 SA 再后过滤”更省资源 但换到功能材料任务,这种相关性显著减弱,直接优化 retrosynthesis 才真正带来优势 所以本文给出的不是一个普遍替代方案,而是一条新的资源分配策略
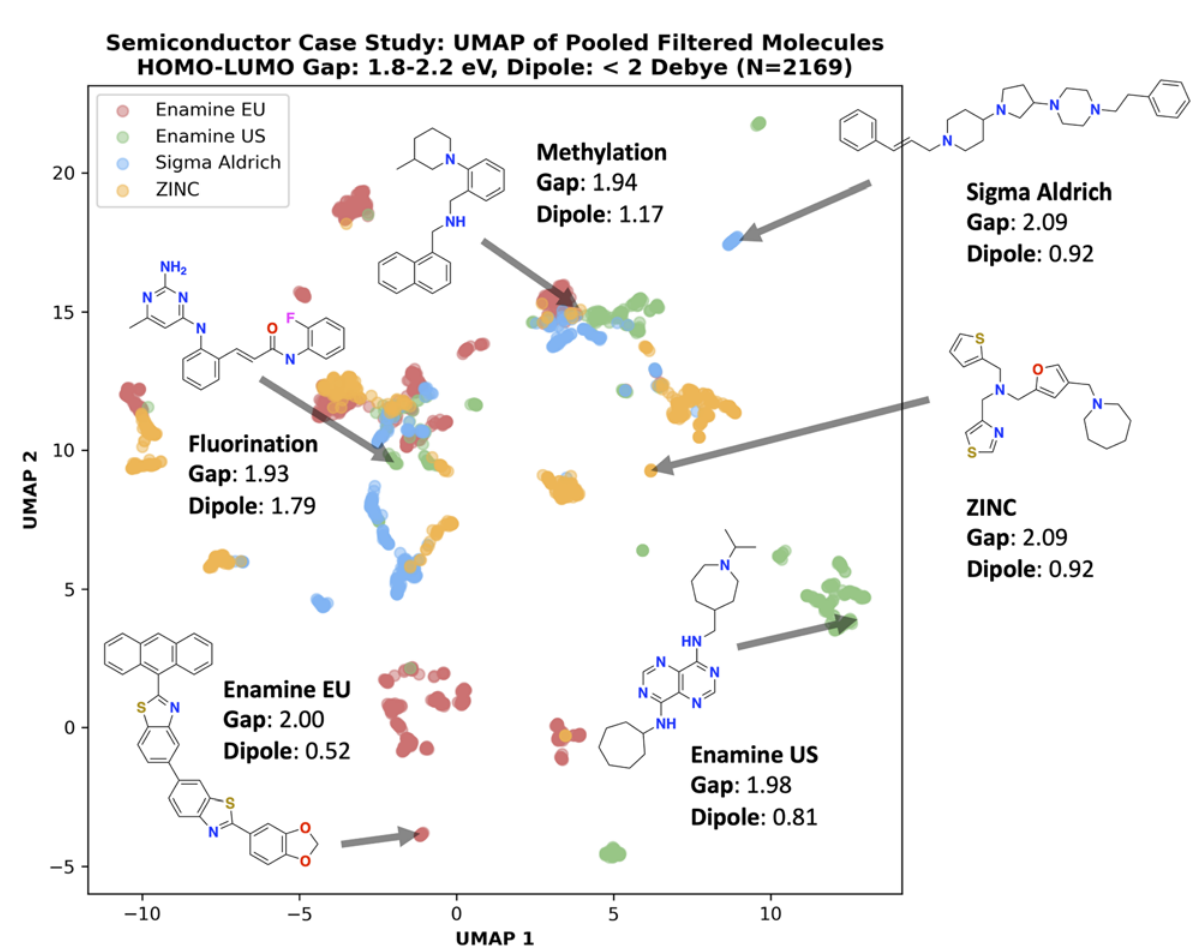
在功能材料任务中,不同 building block stock 会定义不同的“可合成空间”,这也是论文把 stock 当成重要变量的原因 图中的 UMAP 说明,生成结果会随着 stock 的不同进入不同化学区域 这进一步支持作者的判断:当分子空间偏离 PubChem 这类经典药物分布时,SA score 这类启发式会快速失灵 因而在 OOD 化学空间里,retrosynthesis 不只是更贵的 proxy,而是更接近真实目标的信号
最核心结论:只要生成模型足够 sample-efficient,直接把 retrosynthesis 当作优化 oracle 是可行的 但更重要的结论是:这条路线并不总优于启发式,而是在 OOD 化学空间中更有价值 对 drug-like 任务,heuristic + post hoc filtering 仍然是高性价比方案;对功能材料任务,直接优化 retrosynthesis 更可靠 我认为这篇文章最大的贡献不是又做出一个更强模型,而是更清楚地划分了 heuristic 与真实 solvability 的适用边界