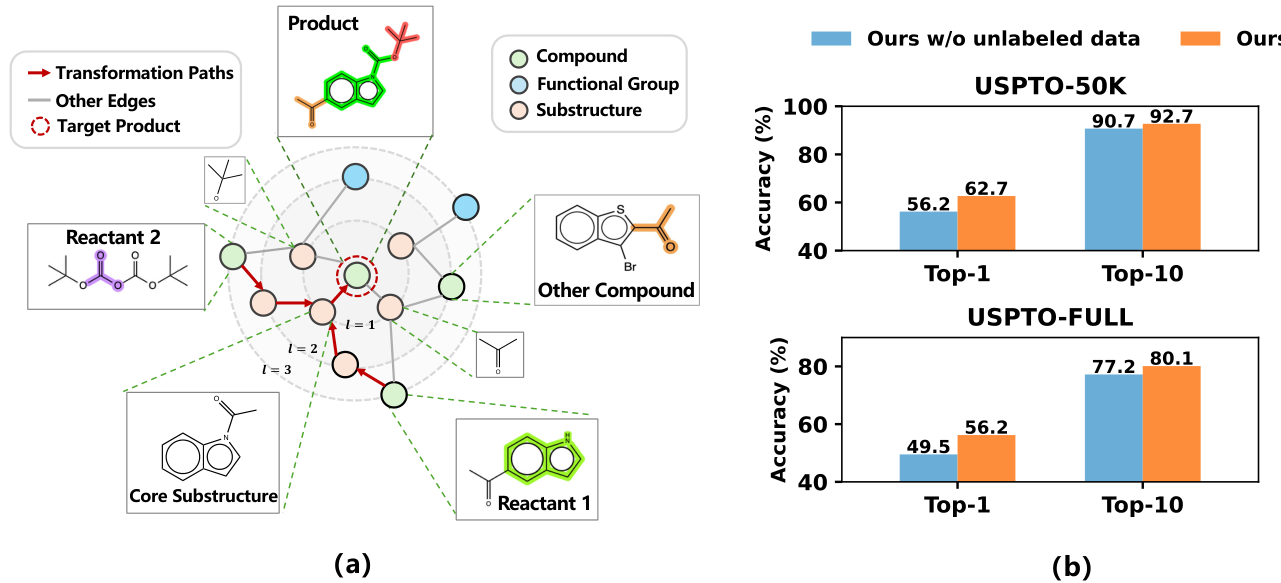
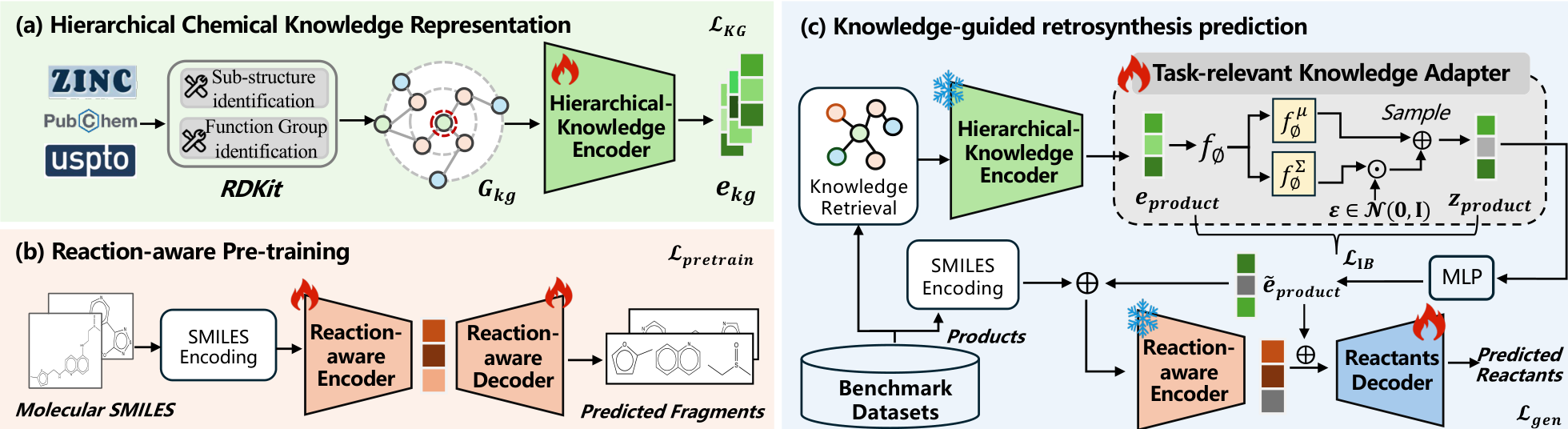
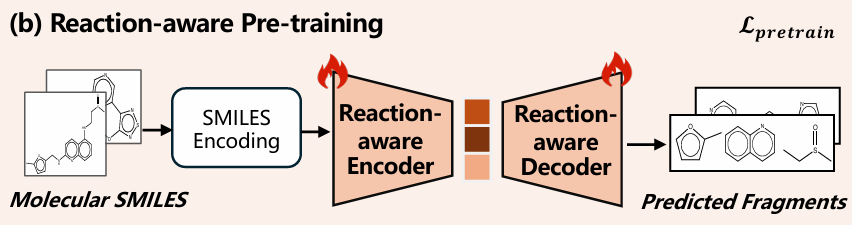
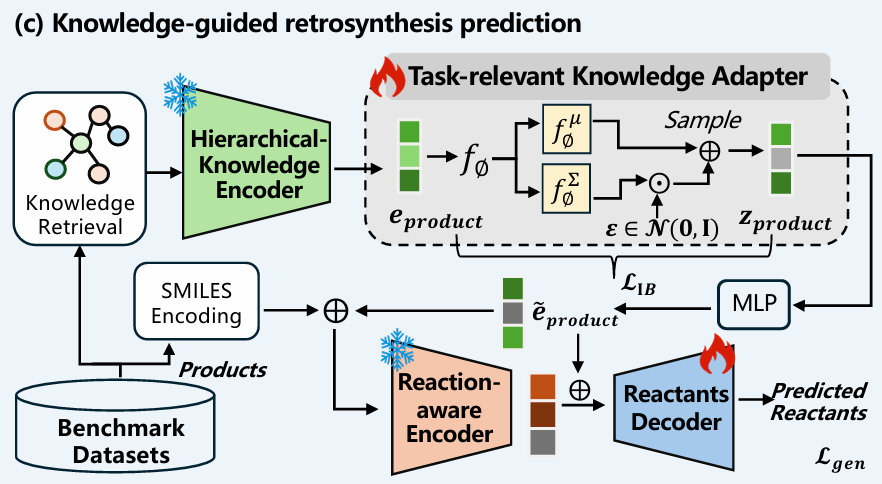
核心思路:从大规模无标签分子中学习化学知识,而不是只依赖反应标签 关键表示:构建分子、子结构、官能团三层知识图谱 关键训练:化学引导预训练 + 任务相关知识适配器 目标效果:同时提升准确性、鲁棒性和多样性
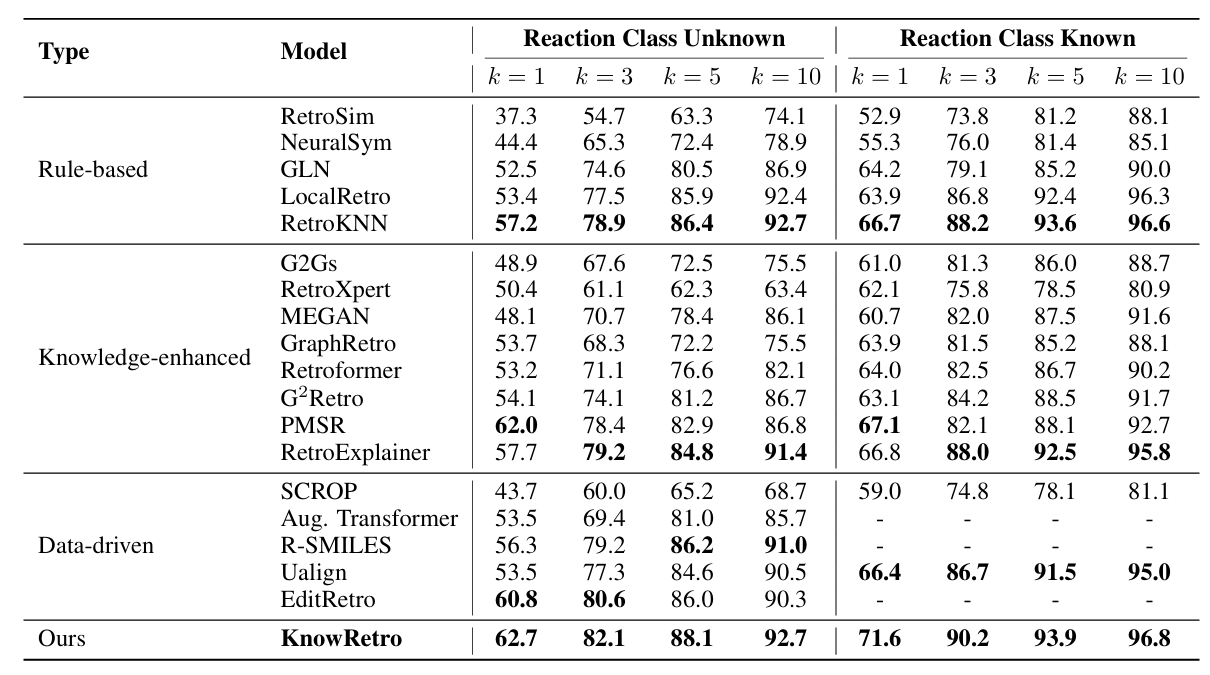
数据集包括 USPTO-50K 和 USPTO-FULL按照反应类型 Unknown 和 Known 两种设定 USPTO-50K Unknown Top-1 达到 62.7% USPTO-50K Known Top-1 达到 71.6% USPTO-FULL Top-1 / Top-10 达到 56.2% / 80.1%
决议结果:Reject,评分分别为 R1=4、R2=6、R3=4 审稿人与 AC 普遍认可:问题有意义、方法有效、实验较充分 rebuttal 后已补充:多步规划、正向反应、性质预测、层次消融、PSM 对照、真实噪声示例 但最终仍被认为:绝对增益有限, novelty 说服力不足 维度 主要优点 主要不足 方法 利用无标签分子学习层次化知识,思路清晰 相比强基线 Top-1 绝对提升不算大 结构设计 KG、预训练、适配器组合有效 模块间统一设计动机最初表达不够清楚 实验 USPTO 结果强,消融和扩展实验较丰富 初版仅聚焦单步任务,跨任务验证不足 可靠性 rebuttal 中补了 stricter negatives 与真实噪声例子 仍缺少公开 Pistachio 测试,外部说服力有限
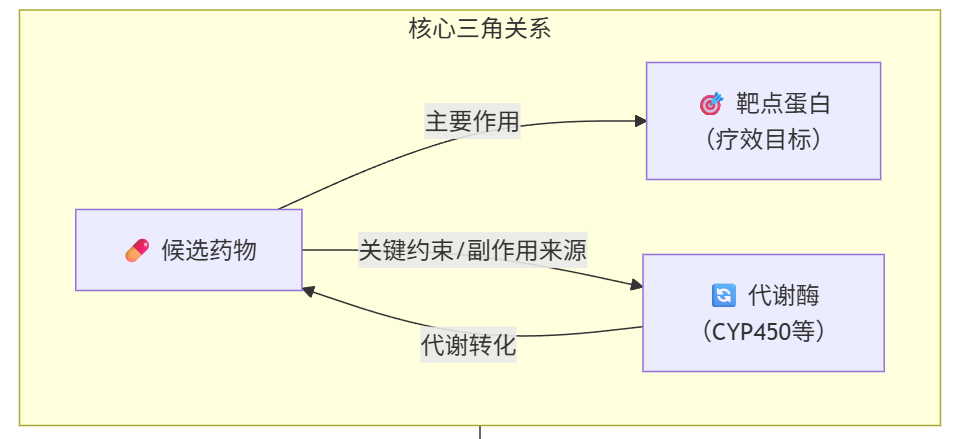
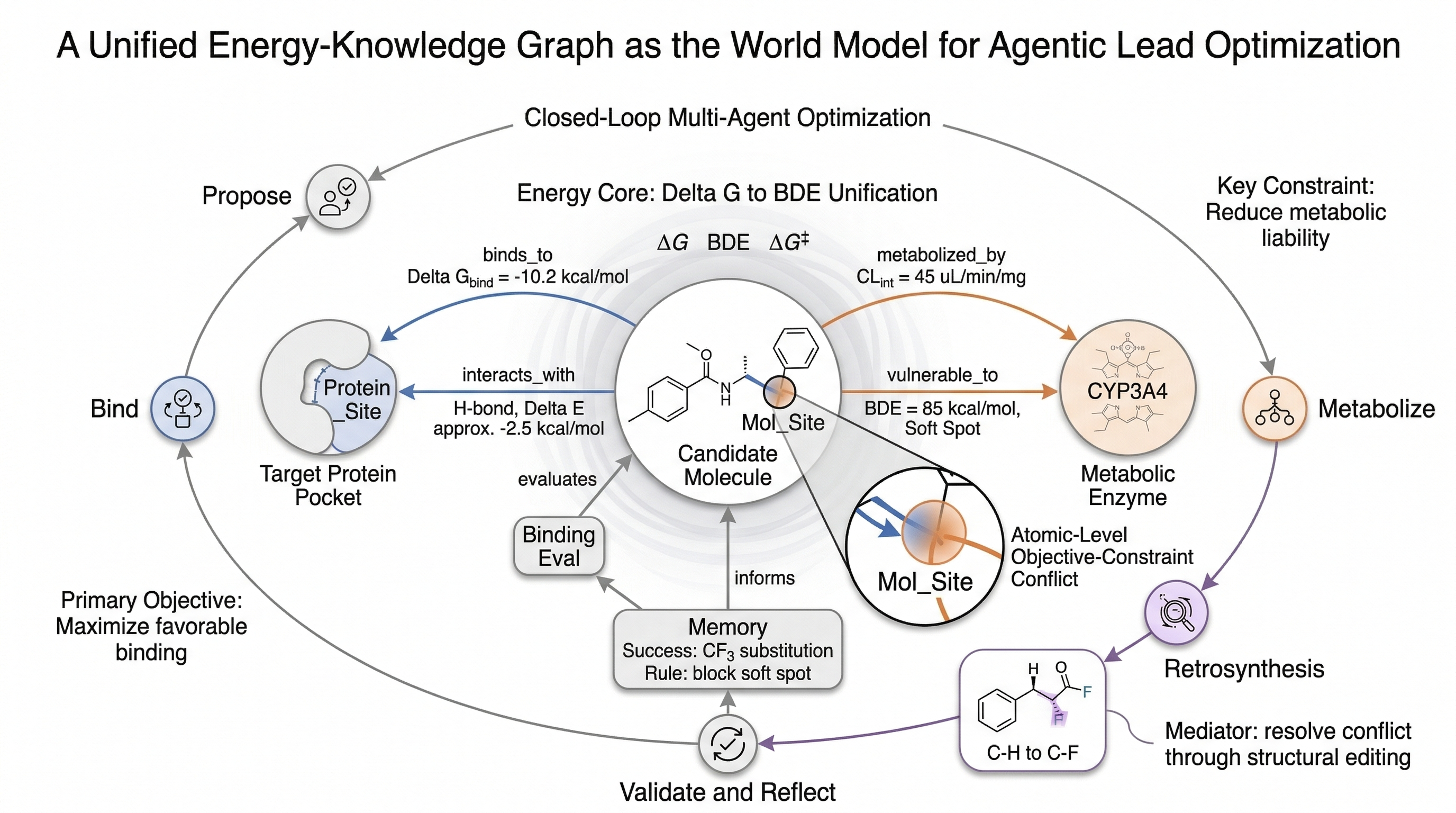
DrugKG 试图把结合、代谢、逆合成放进同一个图结构中 统一能量语义包括 $\Delta G_{bind}$、BDE、$\Delta G^{\ddagger}$ 等关键指标 图中不仅有分子和蛋白,还包含局部化学位点与历史记忆 这样知识图不再只是数据库,而是 Agent 的推理环境
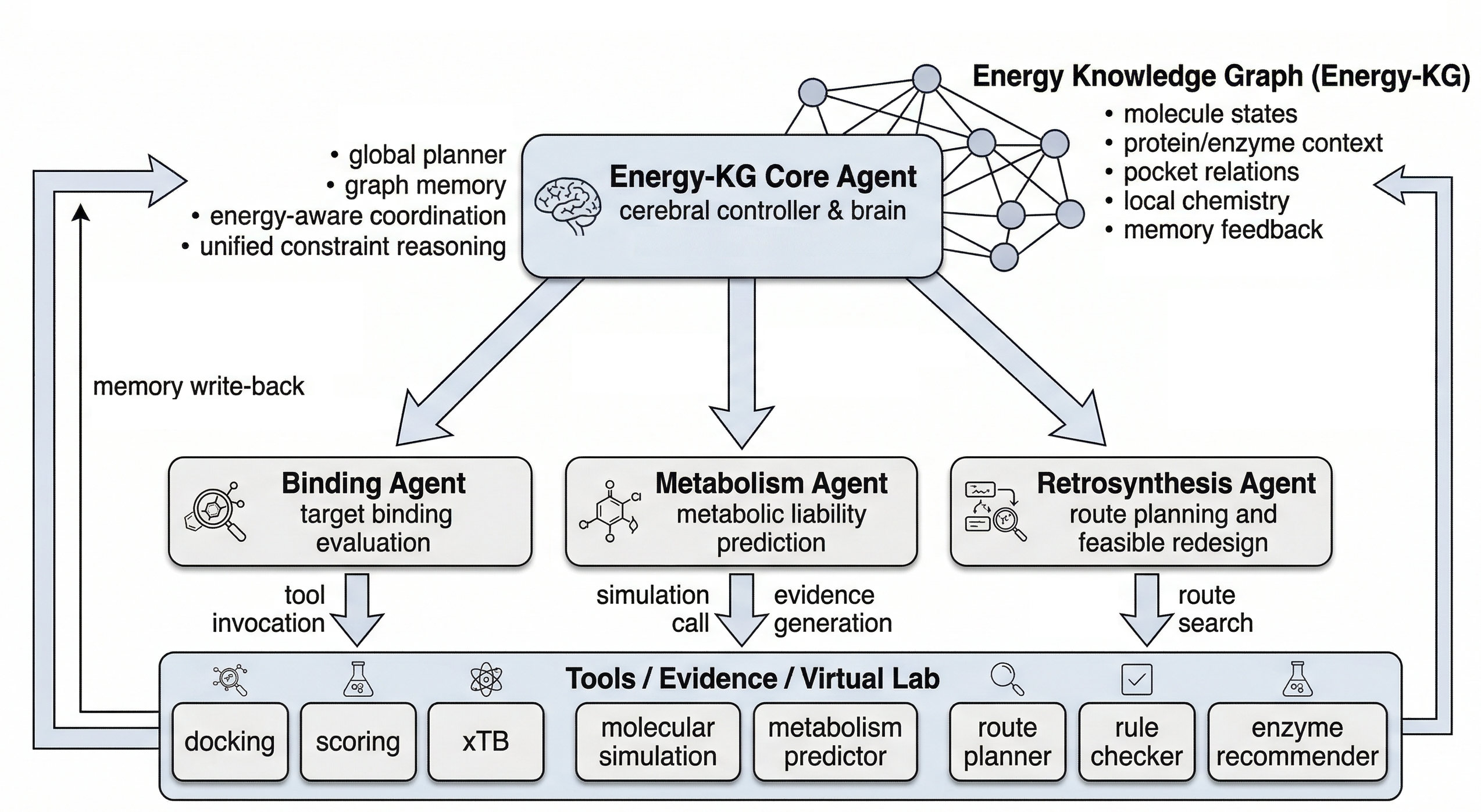
由 DrugKG Core Agent 统一协调 Binding、Metabolism、Retrosynthesis 三类 Agent 三类 Agent 共享同一个图记忆,并把证据持续写回 Binding 负责解释是否有效,Metabolism 负责代谢风险,Retrosynthesis 负责可合成性 最终形成“评估 - 改写 - 验证 - 回写”的闭环优化